With BT currently suffering a lot of negative publicity in the last two days with two major outages caused by power issues in two London datacentres, it is a timely reminder that in the world of communication, networks sometimes break and when they do they have significant repercussions. So more attention to how these networks are built and what underpins the services is as important a buying decision as getting a great commercial deal.
The datacentres concerned are some of the most popular sites in the UK and because of that the knock on impact is significant especially when customers such as BT support so many other partners, businesses and consumers. However BT have appeared to suffer more than others, but anyone within a datacentre can be out for quite a while when hardware is subjected to a power outage, even a brief one, as it can result in hardware not powering back on. With core hardware spending its whole life turned on, the sudden loss in power can result in a high number of failures, requiring engineer visits and hardware replacement – all of which takes time.
Precaution is key, and whether BT had or had not in place sufficient alternative hardware in that datacentre, it did have other working datacentres, so lessons need to be learned about the importance of uptime and mitigating failure where possible. Customers, and especially businesses and ISPs need to understand the risks of not just their networks but upstream suppliers to mitigate total outages. Datacentres for example run large UPS (uninterruptable power supplies) systems to cope with the switch from mains power to generators and while this provides a level of resilience, it needs to be checked and serviced regularly. Servicing and testing varies dramatically between datacentres so investing in smaller UPS systems for individual racks may therefore seem excessive but from experience it can provide a useful buffer should the worse happen.
Furthermore the number of backups and spares again goes someway to reinforce confidence. Gone are the days, in my mind at least, when datacentres can offer n+1 resilience (where ‘n’ is the required load and the +1 means an additional spare). So for example if a datacentre requires four generators to power the site then five would be installed. This is very different to a more resilient site that offers 2n where, for the same example, eight generators would be provided. The big issue with all of this of course is cost and this has a knock-on effect to the customer.
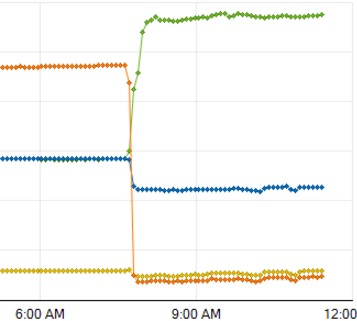
Ultimately though no datacentre is impervious to disaster, as BT and others experienced today, and while a whole site outage is very rare, the importance of having multiple datacentres is very important. While the costs grows significantly again, because not only is everything at least duplicated but now connectivity is required to all the suppliers, the likelihood of complete outage is seriously reduced. The graph shown is all our BT DSL users, with the red line representing customers coming into the affected London datacentre and the green representing our Manchester datacentre also connected to BT’s network. At the time of the failure all our DSL customers moved across meaning they had an outage of a few minutes while their routers would have logged off and on again – significantly better than just relying on London. But as I say having enough spare bandwidth (at least 50% capacity free) dormant for such an occasion, is another cost.
With customers more interested in SaaS applications and outsourcing operations, their removal from the actual nuts and bolts of the network design puts higher reliance on the supplier and the supplier’s supplier to do the right thing in terms of investment and design. Hopefully issues like those experienced today and yesterday will go someway to help steer investment back into resilience.

Leave a Reply